Obiettivi della lezione sui sistemi distribuiti collegati in rete
- Comprendere la classificazione dei sistemi distribuiti. Gli studenti impareranno a identificare e descrivere le diverse tipologie di sistemi distribuiti basate su scopi e architetture, comprendendo le caratteristiche distintive di ciascun tipo.
- Familiarizzare con la terminologia specifica dei sistemi distribuiti. Gli studenti acquisiranno la capacità di utilizzare correttamente il linguaggio tecnico relativo ai sistemi distribuiti, comprendendo i concetti di nodo, latenza, throughput, fault tolerance e altri termini chiave.
- Analizzare i vantaggi e gli svantaggi dei sistemi distribuiti. Gli studenti saranno in grado di valutare criticamente i benefici e le limitazioni dei sistemi distribuiti, applicando questa conoscenza a casi di studio reali e scenari pratici.
Introduzione ai sistemi distribuiti collegati in rete
Un sistema distribuito è un insieme di computer autonomi collegati in rete che collaborano per raggiungere un obiettivo comune. Gli utenti percepiscono il sistema distribuito come un’unica entità coerente. I sistemi distribuiti sono fondamentali nelle infrastrutture moderne, essendo alla base di molte tecnologie come il cloud computing, i database distribuiti e le applicazioni di rete.
I sistemi distribuiti permettono di migliorare le prestazioni, aumentare la disponibilità e garantire la scalabilità delle applicazioni. Essi sono progettati per fornire servizi efficienti e affidabili, distribuendo il carico di lavoro su diversi nodi.
Un sistema distribuito può includere server, desktop, dispositivi mobili e qualsiasi altra risorsa di calcolo collegata in rete. Questi sistemi possono variare notevolmente in scala e complessità, dai piccoli cluster di server alle grandi reti globali di data center utilizzati dai giganti tecnologici come Google e Amazon.
Classificazione dei sistemi distribuiti
La classificazione dei sistemi distribuiti può essere fatta su diverse basi:
Classificazione per scopo:
- Sistemi distribuiti di calcolo: Utilizzati per risolvere problemi computazionalmente intensivi. Un esempio è il cluster di calcolo, dove molteplici nodi collaborano per eseguire calcoli complessi. Questi sistemi sono utilizzati in applicazioni come la simulazione scientifica, il rendering di grafica 3D e l’analisi di grandi quantità di dati. Nel cluster di calcolo, ogni nodo esegue una parte del lavoro complessivo, permettendo di affrontare problemi che richiederebbero tempi di elaborazione proibitivi su un singolo computer.
- Sistemi distribuiti di dati: Progettati per gestire grandi quantità di dati distribuiti su più nodi. Un esempio è un database distribuito che consente l’accesso ai dati da diverse posizioni geografiche. Questi sistemi sono fondamentali per applicazioni come i servizi bancari, l’e-commerce e i social network, dove la disponibilità e la consistenza dei dati sono cruciali. In un database distribuito, i dati sono replicati e distribuiti tra più nodi per garantire l’accesso rapido e affidabile.
Classificazione per architettura:
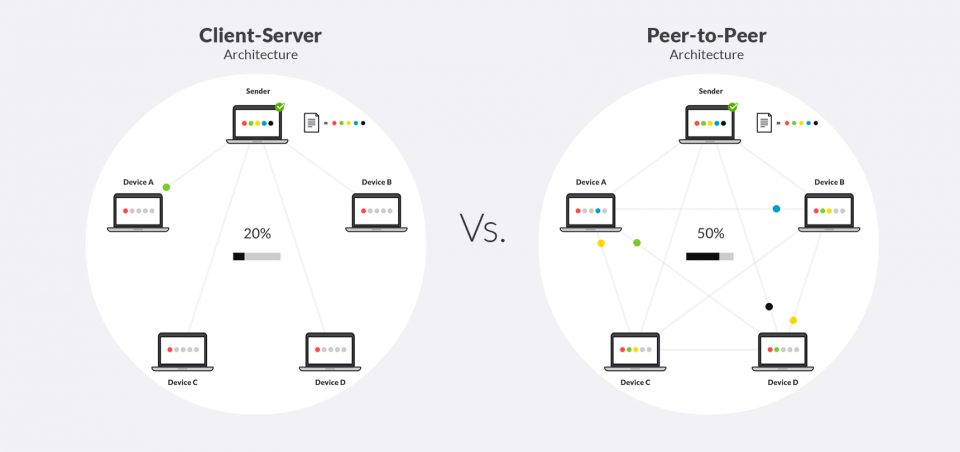
- Client-server: Una struttura dove i client richiedono servizi e i server forniscono questi servizi. Questo modello è comune in applicazioni web e di rete. I client inviano richieste al server, che elabora queste richieste e restituisce i risultati. Questo modello è utilizzato per le applicazioni web, i servizi di posta elettronica e i database centralizzati. L’architettura client-server può variare da configurazioni semplici con un singolo server e pochi client, a sistemi complessi con molteplici server e migliaia di client.
- Peer-to-peer (P2P): Ogni nodo nel sistema può agire sia da client che da server. Questo modello è utilizzato in reti di condivisione di file come BitTorrent. In un sistema P2P, i nodi possono condividere risorse direttamente tra loro senza la necessità di un server centrale, migliorando la scalabilità e la resilienza del sistema. Le reti P2P possono essere utilizzate anche per applicazioni di comunicazione e collaborazione, come i sistemi di messaggistica istantanea e le piattaforme di videoconferenza.
Terminologia dei sistemi distribuiti
Alcuni termini chiave nel contesto dei sistemi distribuiti collegati in rete includono:
- Nodo: Un dispositivo indipendente nel sistema, che può essere un computer, server o altro dispositivo di rete. I nodi collaborano per eseguire compiti specifici e condividono risorse come CPU, memoria e spazio di archiviazione. In un sistema distribuito, ogni nodo può essere configurato per svolgere ruoli specifici, come l’elaborazione dei dati, l’archiviazione o la gestione della rete.
- Latenza: Il tempo impiegato per un dato per viaggiare da un punto all’altro nella rete. Bassa latenza è cruciale per applicazioni in tempo reale come la videoconferenza e i giochi online. La latenza può essere influenzata da vari fattori, inclusa la distanza fisica tra i nodi e la qualità della connessione di rete. La latenza è un parametro critico per la qualità del servizio (QoS) nelle reti di telecomunicazione e nelle applicazioni distribuite.
- Throughput: La quantità di dati che possono essere trasferiti in un intervallo di tempo specificato, misura la capacità del sistema. Un alto throughput è essenziale per applicazioni che richiedono il trasferimento di grandi quantità di dati, come lo streaming video e il backup di dati. Il throughput è influenzato dalla capacità della rete, dalla gestione della congestione e dall’efficienza dei protocolli di comunicazione.
- Fault tolerance: La capacità di un sistema di continuare a funzionare correttamente anche in presenza di guasti. Questa è una caratteristica critica per i sistemi distribuiti ad alta disponibilità. La tolleranza ai guasti può essere ottenuta attraverso la ridondanza, il mirroring dei dati e l’uso di algoritmi di consenso che permettono al sistema di continuare a operare anche se alcuni nodi falliscono. I meccanismi di fault tolerance sono essenziali per garantire la continuità del servizio e la protezione dei dati in caso di guasti hardware o software.
Vantaggi dei sistemi distribuiti
- Scalabilità: I sistemi distribuiti possono facilmente scalare orizzontalmente aggiungendo nuovi nodi, migliorando la capacità di elaborazione e archiviazione senza sostituire l’hardware esistente. La scalabilità permette di gestire aumenti del carico di lavoro senza degradare le prestazioni. Ad esempio, un sito web può aumentare il numero di server per gestire un maggiore traffico durante eventi promozionali o stagionali.
- Affidabilità: La ridondanza nei sistemi distribuiti aumenta la tolleranza ai guasti, poiché i dati e i servizi possono essere replicati su più nodi. Se un nodo fallisce, altri nodi possono prendere il suo posto. Questo aumenta la disponibilità del sistema e riduce il rischio di interruzioni del servizio. I sistemi distribuiti utilizzano tecniche come la replica dei dati, il failover automatico e i protocolli di consenso per garantire la disponibilità e l’integrità dei dati.
- Flessibilità: I sistemi distribuiti possono integrare nuove tecnologie e componenti senza interrompere l’intero sistema. Questo permette un’implementazione graduale e la possibilità di adattarsi rapidamente a nuove esigenze. Ad esempio, è possibile aggiornare o sostituire i nodi senza dover spegnere l’intero sistema. La flessibilità è un vantaggio significativo per le organizzazioni che devono adattarsi rapidamente ai cambiamenti del mercato o alle innovazioni tecnologiche.
- Prestazioni: Le operazioni possono essere eseguite in parallelo su più nodi, migliorando le prestazioni complessive del sistema, specialmente per applicazioni che richiedono elevata capacità computazionale. Questo è particolarmente utile per applicazioni che eseguono operazioni di elaborazione dati su larga scala. L’esecuzione parallela permette di ridurre i tempi di elaborazione e di migliorare l’efficienza complessiva del sistema.
Svantaggi dei sistemi distribuiti collegati in rete
- Complessità: La gestione e la progettazione dei sistemi distribuiti collegati in rete possono essere complesse. La necessità di coordinare le attività tra nodi, gestire la comunicazione e la coerenza dei dati richiede una progettazione accurata e sofisticata. Questo aumenta il tempo e le risorse necessarie per sviluppare e mantenere il sistema. La complessità può anche aumentare i costi di sviluppo e di gestione, rendendo più difficile la risoluzione dei problemi e il debugging del sistema.
- Sicurezza: Aumenta la superficie di attacco a causa della distribuzione dei dati e delle risorse. Proteggere tutte le componenti del sistema e garantire la sicurezza dei dati in transito richiede misure di sicurezza avanzate. La sicurezza deve essere considerata a livello di rete, applicazione e dati. La distribuzione dei dati su più nodi rende necessario l’uso di crittografia, autenticazione e autorizzazione per proteggere le informazioni sensibili.
- Coerenza dei dati: Mantenere la coerenza dei dati attraverso nodi distribuiti è una sfida significativa. Problemi come la latenza di rete possono causare incoerenze temporanee nei dati replicati. La coerenza dei dati è cruciale per garantire che tutti i nodi abbiano una visione uniforme dei dati. Gli algoritmi di coerenza, come i protocolli di consenso e la replica dei dati, sono utilizzati per garantire che le operazioni di lettura e scrittura siano eseguite in modo coerente su tutti i nodi.
- Costi: I costi per infrastruttura e manutenzione possono essere elevati, specialmente quando si considerano le spese per l’hardware, il software, la rete e la gestione. La necessità di ridondanza e tolleranza ai guasti aumenta ulteriormente i costi operativi. Le organizzazioni devono investire in infrastrutture di rete robuste, strumenti di gestione e personale qualificato per mantenere e operare sistemi distribuiti.
Architettura client-server

I sistemi distribuiti collegati in rete sono basati su un’architettura client/server. Tale architettura è costituito da un insieme di host che gestiscono una (o più) risorse, i server, e da un insieme di client che richiedono l’accesso ad alcune risorse distribuite gestite dai server. Inoltre ogni processo server può a sua volta diventare client per richiedere accesso ad altre risorse gestite da altri (processi) server.
Nel modello client/server, la comunicazione avviene attraverso lo scambio di messaggi.
Un server è in ascolto tramite un socket su una determinata porta in attesa di richiesta di connessione da parte di un client. Un client, quindi, per comunicare con un server usando il protocollo TCP/IP deve, per prima cosa, “connettersi” al socket dell’host dove il server è in esecuzione specificando l’indirizzo IP della macchina e il numero di porta sulla quale il server è in ascolto.
Le architetture client-server sono normalmente organizzate a “livelli” (tier) dove ogni livello corrisponde a un nodo o gruppo di nodi di calcolo su cui è distribuito il sistema: ciascun livello funziona da server per i suoi client nel livello precedente e da client per il livello successivo ed è organizzato in base al tipo di servizio che fornisce.
Tipologie di architettura client-server
Possono essere suddivise in tre livelli applicativi (sw):
- Presentazione (front-end o presentation tier): gestisce le modalità di interazione con l’utente. viene anche detto Presentation Layer (PL). Nei sistemi Web che visualizzano pagine HTML, il Presentation Layer è costituito dai moduli del web server che concorrono a creare i documenti HTML, come gli script PHP, mentre il client può essere identificato con il browser;
- Logica applicativa o middle tier: gestisce le funzioni da mettere a disposizione dell’utente;
- Logica di accesso (back-end o data tier): gestisce l’informazione con eventuale accesso alla base di dati e può essere implementata tramite un DBMS, in questo caso prende il nome di Data Access Layer (DAL).
Architettura N-Tier
Un’applicazione distribuita può essere configurata come:
- Architettura a un livello – 1 tier: i tre livelli si trovano su un’unica macchina; Questa architettura non rientra nella tipologia client-server e può essere classificata come architettura a un solo livello;
- Architettura a due livelli – 2 tier: i tre livelli sono divisi tra una macchina client e una macchina server. Si possono individuare due sottocategorie di architetture a due livelli:
3. Architettura a tre livelli – 3 tier: ogni livello si trova su una macchina dedicata. Le macchine comunicano tra loro grazie al livello relativo alla logica applicativa che svolge il ruolo di middleware ed ha lo scopo di realizzare la comunicazione e le interazioni tra i diversi componenti software del sistema distribuito. I vantaggi dell’introduzione del middleware sono notevoli, soprattutto in termini di prestazioni, in quanto in questo modo si favorisce la distribuzione della quantità di elaborazione a scapito, però, dei tempi di comunicazione. Inoltre il sistema è facilmente scalabile in quanto all’aumentare delle richieste di un servizio è possibile aggiungere qualche server in grado di compensare il carico di lavoro ed è inoltre più tollerante ai guasti. Anche in termini di sicurezza il modello a tre livelli porta notevoli vantaggi in quanto rende possibile l’introduzione di sicurezza a livello di servizio e quindi più facilmente gestibile. Nei sistemi 3 tier, data la loro maggiore complessità. è però più difficile la loro progettazione, lo sviluppo e l’amministrazione;
4. Architettura a n tier: le architetture client-server a N livelli sono una generalizzazione del modello client-server a tre livelli dove vengono scomposti e introdotti un numero qualunque di livelli e server intermedi.